Where motion becomes intelligence.
thousands of high-quality, labeled synthetic frames from one of the world's largest mocapped exercise datasets
Request Data SampleReal Biomechanical Foundation
600
Exercises
6,000
Good Posture Variations
68,400
Total Repetitions
16,800
Postural Errors
From Raw Mocap to AI-Ready Data

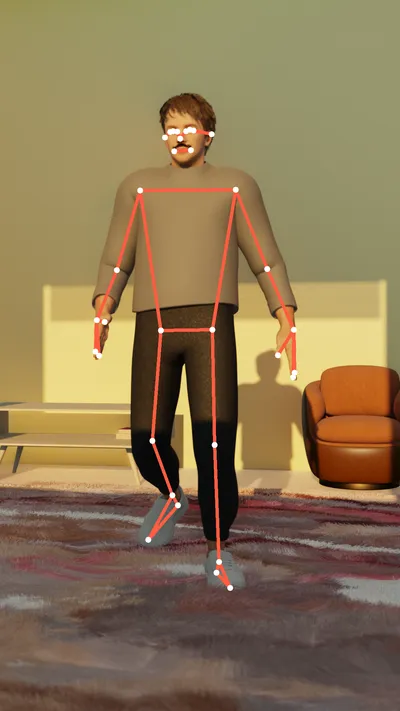

Generate body keypoints in different formats: Coco and Mediapipe.

Automatically generate perfect depth maps for 3D model training.

Pixel-perfect segmentation, generated automatically.
THE FUEL FOR YOUR INNOVATION
Fitness Technology
Power your fitness app with AI that understands real human movement. Provide users with accurate rep counting, form correction, and real-time feedback.
MSK Digital Health
Develop next-generation digital health solutions for musculoskeletal (MSK) care, remote physiotherapy, and ergonomic analysis with clinically-validated data.
Innovation Labs
Fuel your R&D for any application that involves human motion. From AR/VR experiences to robotics, our data provides the ground truth you need to innovate.
Targeting Customer Pain Points

Training a model requires vast, perfectly labeled data. Manually, this means renting expensive mocap studios, hiring professional athletes, paying specialists to revise captured video and signal pose transitions, and then paying an annotation team to label every single frame in 2D. This process is slow, astronomically expensive, and must be repeated for every new exercise or feature.
Our pipeline eliminates this cost. And bypasses the traditional, error-prone 2D annotation process entirely. You get a production-ready 3D dataset for a fraction of the cost, saving you hundreds of thousands of dollars and months of work.

Your model works perfectly in your lab, but fails in the real world. Why? Because you couldn't capture every possible real-world scenario. Your training data is limited by the specific people, lighting, and environments you recorded. Your model has never seen users with different body types, in cluttered living rooms, or in low-light conditions.
Our synthetic pipeline algorithmically generates the variability you can't capture manually. We create thousands of permutations for each movement:
- Users: Countless body shapes (BMI), skin tones, and clothing (t-shirts, hoodies, shorts).
- Environments: Bright gyms, dark bedrooms, cluttered living rooms, abstract backgrounds.
- Camera: Any angle, height, focal length, and distance.
This "Domain Randomization" ensures your model is robust and performs for all your users, not just the ones who look like your test subjects.
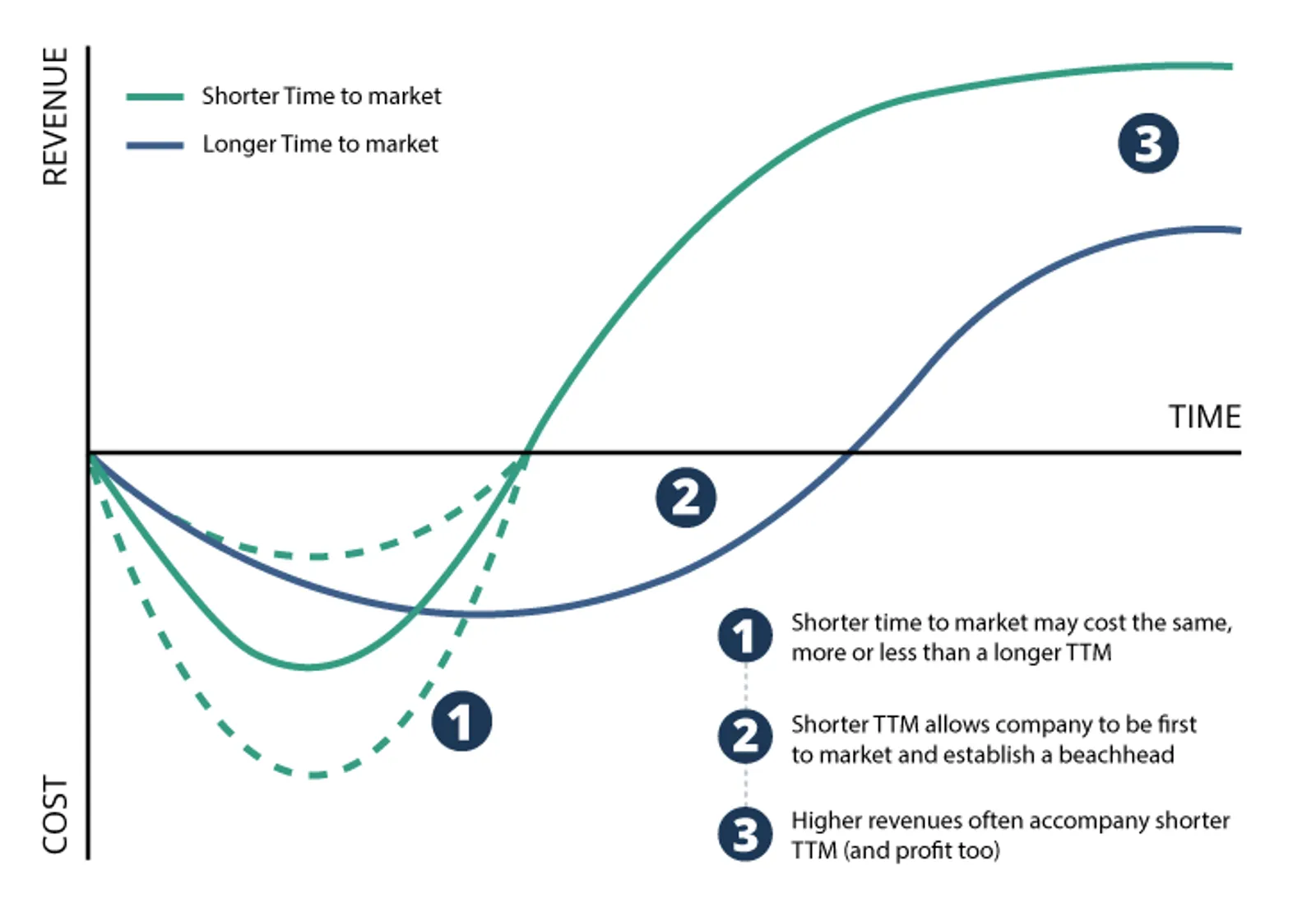
Your competitor just launched a new form-correction feature. Your team estimates it will take 9-12 months to collect and label enough data to build your own. By then, you've lost your first-mover advantage. This "data bottleneck" is the single biggest blocker to AI innovation.
We turn your data bottleneck into a data highway. You can have a production-ready, enterprise-scale dataset in a couple of weeks. Instead of spending 12 months on data collection, your engineers can spend that time on what truly matters: building, training, and deploying your model. Launch new features, new exercises, and new products in a fraction of the time.

Collecting real-world user video is a legal and ethical minefield. You have to navigate a complex web of privacy laws like GDPR and HIPAA. A single data breach could be catastrophic, costing millions in fines and destroying your users' trust.
Our data is 100% synthetic and anonymous. It contains no Personally Identifiable Information (PII)—no real faces, no real bodies. This completely eliminates all privacy and compliance risks. You can train and deploy your models with zero legal liability, ensuring your company and your users are fully protected.
Your model is only as good as its labels. When you use a human annotation team (or worse, crowdsourcing), you get inconsistencies, subjective errors, and bias. Annotator A labels a keypoint 5 pixels differently than Annotator B. The "ground truth" is noisy and unreliable, leading to a model that is less accurate and performs poorly on edge cases.
Our data is algorithmically perfect. Every single frame is labeled by our pipeline with sub-pixel accuracy. The keypoint for the left elbow is in the exact same corresponding 3D space, every time. This provides a perfectly clean, objective, and consistent "ground truth" for your model, resulting in higher accuracy, faster training convergence, and more reliable performance.
Flexible Plans for Every Stage
Foundation
(12 month license)
150K FRAMES
What's Included:
- 30 exercise types from mocap library
- 5K synthetic frames per exercise
- Standard environmental/user variations
- Standard annotation formats
- Basic domain randomization parameters
Professional
(24 month license)
2M FRAMES
What's Included:
- 200 exercise types from mocap library
- 10K synthetic frames per exercise
- Full environmental/user/movement variation
- Technical integration support
- Advanced domain randomization
- Priority email/video support
Enterprise
(36 month license)
10M+ FRAMES
What's Included:
- 600+ exercise types from full mocap library
- 20K synthetic frames per exercise
- Negotiable mocap library access
- Custom exercise additions
- Multi-industry coverage
- Quarterly dataset updates
See the Technology in Action
FREQUENTLY ASKED QUESTIONS
AGIT represents a unique market opportunity born from authentic founder-market fit. Originally developing a fitness app, we encountered the fundamental bottleneck plaguing every computer vision company: insufficient training data for production-grade models. We discovered our true competitive advantage lies not in building another consumer app, but in solving the critical data infrastructure problem for the entire industry.
Synthetic data isn't "fake"; it's "engineered." Our pipeline starts with 100% real, professional-grade motion capture (mocap) data, which serves as our "ground truth." We then algorithmically transform this data to create thousands of variations—different body types, camera angles, lighting, environments, and clothing—all while preserving the core biomechanical accuracy.
Our entire library is built on a "Real Biomechanical Foundation." This foundation comes from 2+ years of R&D and investment in one of the world's largest mocap exercise datasets. Every synthetic variation originates from a real, accurately performed motion. We don't guess at movement; we augment reality.
Our datasets are ready to train. We provide rendered RGB video frames, depth maps, segmentation masks, and pixel-perfect 2D/3D keypoints (in formats like COCO and MediaPipe). This multi-modal data is pre-labeled, saving you thousands of hours in manual annotation.
We do both, which is crucial for building effective models. Our library includes thousands of the most common postural errors for each exercise (e.g., "arched back" in a squat, "flared elbows" in a push-up). This allows you to train your AI to not only recognize an exercise but to accurately correct a user's form.
Our data is for AI/ML teams, data scientists, and engineers building applications that require an understanding of human motion. Our primary customers are in Fitness Technology (for rep counting/form correction), MSK Digital Health (for remote physiotherapy/ergonomics), and corporate R&D/Innovation Labs.
We license our datasets on an annual basis (typically 12, 24, or 36 months). This license allows your team to use the data for all internal R&D, model training, and for deployment in your final commercial application. The data itself cannot be resold or redistributed.
Because our data is 100% synthetic, it contains no "Personally Identifiable Information" (PII). There are no real faces, bodies, or personal data. This completely bypasses all compliance issues related to GDPR, HIPAA, and other privacy regulations, which is a major advantage over collecting real-world user data.
Our full library contains over 600 unique exercises. Our "Foundation" and "Professional" plans provide access to a subset of this library. For our "Enterprise" clients, we offer access to the full library as well as the option to commission custom exercise additions.
We encourage all potential customers to test a sample of our data. Please use the "Contact Sales" or "Request Data Sample" buttons on our website, and a member of our team will get in touch to understand your needs and provide a relevant data slice for your evaluation.